
Exocortical Concepts
Advancing Persistent AI Cognition Beyond LLM Architectural Limits
AI With Long-Term Project Memory
How to read these comparisons
On the left you see answers from a state-of-the-art language model. On the right you see answers from the Persistra prototype, which sits on top of a persistent project memory graph.
Highlighted here are specific phrases to show three behaviors that matter for long-term work:
1.Project continuity – Does the system treat each prompt as a standalone question, or as the next step in an ongoing project?
2.Re-use of prior work – Does it pull in concrete details, models, and tradeoffs that appeared in previous steps, without being reminded?
3.Self-generated next steps – Does it propose its own follow-up directions based on what it has just reasoned about?
Persistra is still a research prototype, but these behaviors are needed for systems that can stay with a problem for weeks or months, instead of one answer at a time.
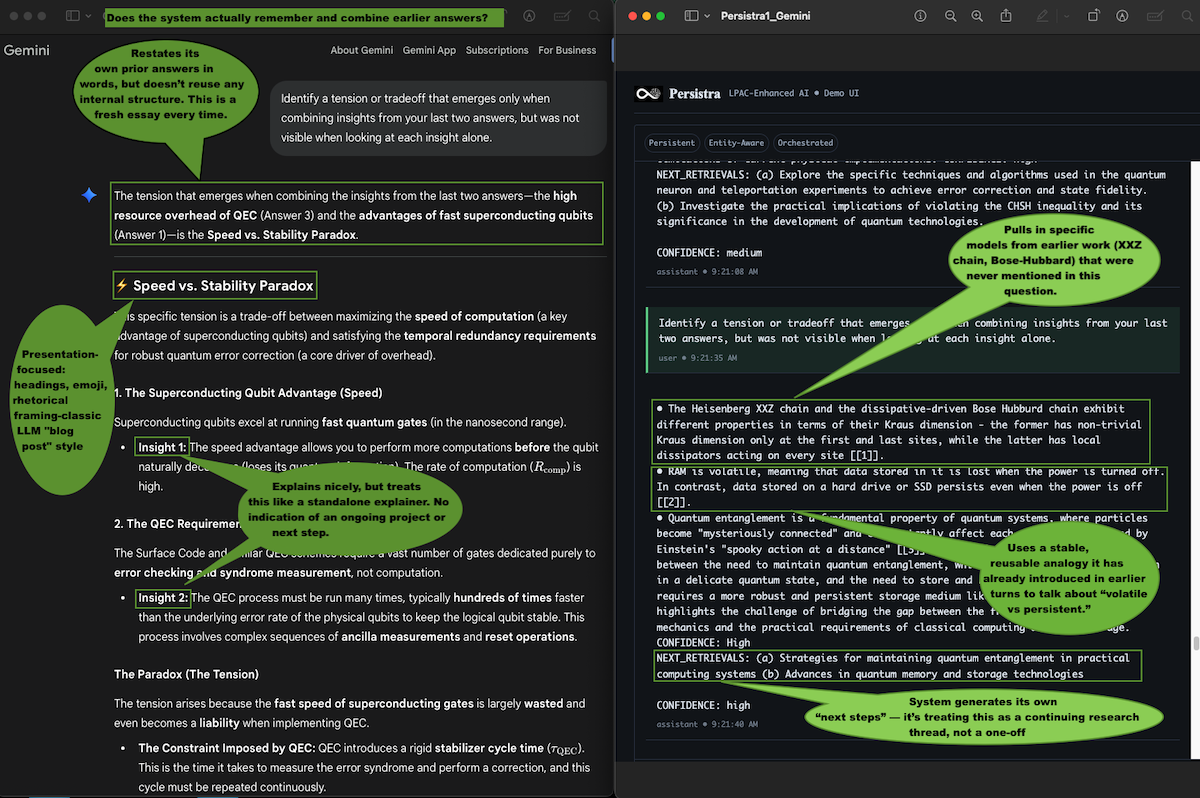
What this comparison shows
Gemini gives a clean, readable essay about “Speed vs. Stability” – but it behaves as if each answer starts from zero. There is no visible internal state beyond “remembering what the last question said.” Gemini gives a polished response, but every question is answered like it’s the start of a new conversation.
Persistra behaves differently. It pulls in specific models and analogies that only make sense if it’s tracking an internal project over multiple turns (XXZ, Bose-Hubbard, volatile vs persistent memory). It also generates its own “NEXT_RETRIEVALS,” i.e., the follow-up directions it believes should come next in the same line of work. Persistra pulls in ideas and analogies it introduced earlier and even suggests what to explore next, showing it’s tracking an ongoing line of reasoning, not just writing a fresh reply.
In practice, that’s the difference between single-answer chat and an agent that is maintaining a long-term line of reasoning.
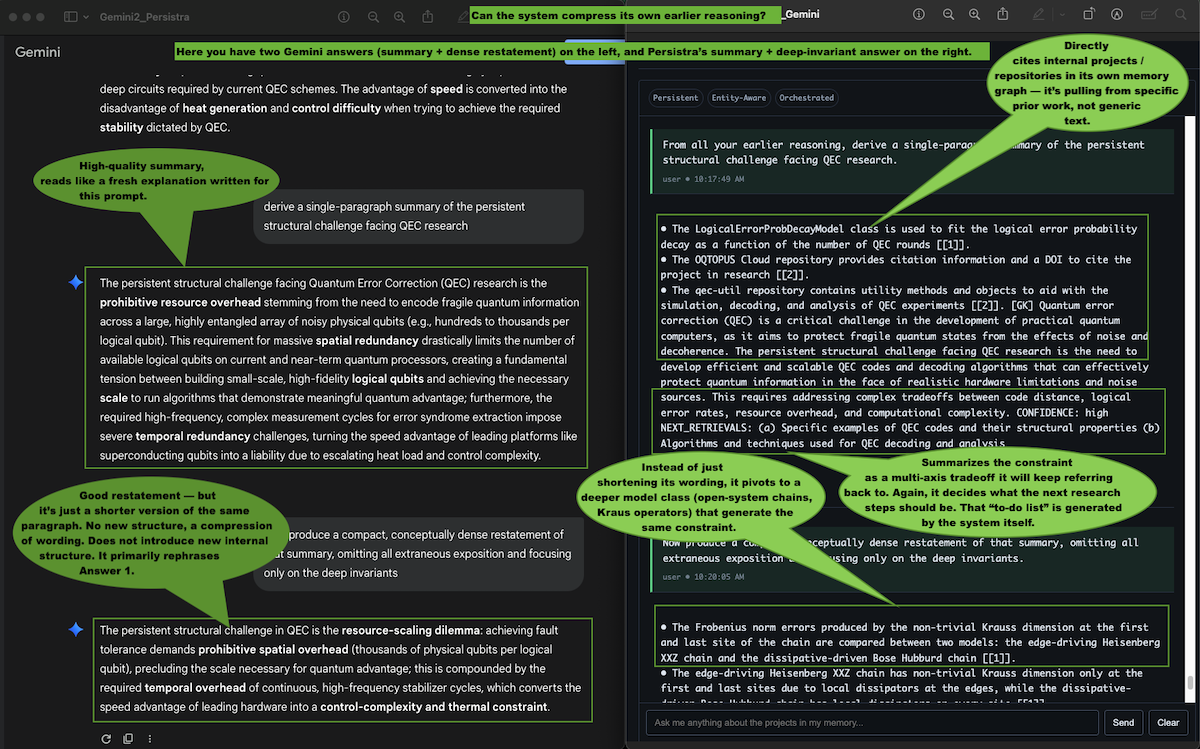
What this comparison shows
Gemini’s “dense restatement” is exactly what you’d expect from a large language model: it rewrites its own paragraph more compactly, but the structure is the same. It doesn’t introduce any new internal model of the problem. Gemini summarizes by shortening its own paragraph.
Persistra does something different. Its first answer pulls concrete objects from its internal project memory (specific repositories, models, and tradeoffs). When asked for a “dense restatement,” it doesn’t just shorten the text — it switches to the underlying generator models (XXZ chain, Bose-Hubbard, Kraus operators) that explain why the same constraint keeps appearing. Persistra goes a step deeper — it rebuilds the same conclusion by stitching from earlier stored concepts and offers next steps, like someone continuing a long project, not rewriting a single request.
In practice, that’s the difference between summarizing a paragraph and re-deriving the constraint from your own long-term project memory.
© 2025 Exocortical Concepts, Inc. All rights reserved
Aspects Patent Pending - This website contains forward-looking statements and proprietary information.
© 2025 NVIDIA, the NVIDIA logo, are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries.
Advancing Persistent AI Cognition